Autori
Gabriele Costante, Michele Mancini, Paolo Valigi and Thomas Alessandro Ciarfuglia
Abstract
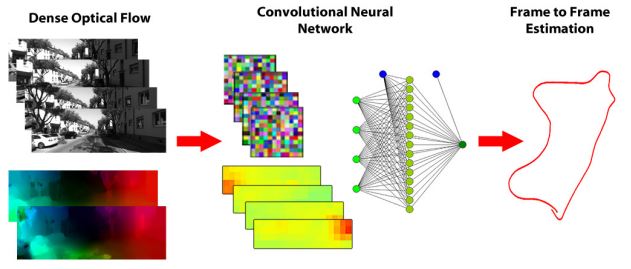
Visual Ego-Motion Estimation, or briefly Visual Odometry (VO), is one of the key building blocks of modern SLAM systems. In the last decade, impressive results have been demonstrated in the context of visual navigation, reaching very high localization performance. However, all ego-motion estimation systems require careful parameter tuning procedures for the specific environment they have to work in. Furthermore, even in ideal scenarios, most state-of-the-art approaches fail to handle image anomalies and imperfections, which results in less robust estimates. VO systems that rely on geometrical approaches extract sparse or dense features and match them to perform Frame to Frame (F2F) motion estimation. However, images contain much more information that can be used to further improve the F2F estimation. To learn new feature representation a very successful approach is to use
deep Convolutional Neural Networks. Inspired by recent advances in Deep Networks and by previous work on learning methods applied to VO, we explore the use of Convolutional Neural Networks to learn both the best visual features and the best estimator for the task of visual Ego-Motion Estimation. With experiments on publicly available datasets we show that our approach is robust with respect to blur, luminance and contrast anomalies and outperforms most state-of-the-art approaches even in nominal conditions.




