Autori
Silvia Cascianelli, Gabriele Costante, Enrico Bellocchio, Paolo Valigi, Mario Luca Fravolini and Thomas Alessandro Ciarfuglia
Abstract
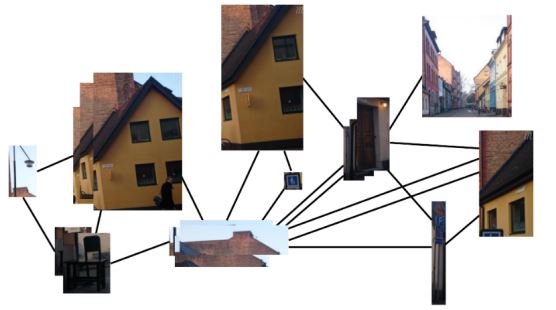
This talk provides a new contribution to the problem of vision-based place recognition introducing a novel environment agnostic, appearance and viewpoint invariant approach that guarantees robustness with respect to perceptual aliasing and kidnapping. Most of the state-of-the-art strategies rely on low level visual features and ignore the semantical structure of the scene. Thus, even small changes in the appearance cause a significant performance drop. We propose a new strategy to model the scene by preserving its geometrical and the semantical structure and, at the same time, achieving an improved appearance invariance through a robust visual representation. In particular we introduce a covisibility graph, that connects semantical entities of the scene preserving their geometrical relations. The method relies on high level patches consisting of dense and robust descriptors that are extracted by a Convolutional Neural Network (CNN). Through the graph structure, we are able to efficiently retrieve candidate locations and to synthesize virtual locations (i.e., artificial intermediate views between two keyframes) to improve the viewpoint invariance. The proposed approach has been compared with state-of-the-art approaches in different challenging scenarios taken from public datasets.




